
データクリーニング(前処理)において外れ値除去は非常に重要です。
重回帰分析や機械学習では、データのクリーニングが全体の8割を閉める重要な仕事と位置付ける人もいます。
ちょうど、手術でいう、術前計画にあたるのでしょうか?
- データクリーニングのステップ
- データクリーニングが解析の8割!
- 外れ値除去における注意点

Python2年生 データ分析のしくみ 体験してわかる! 会話でまなべる!
他にも、Udemy
・【世界で34万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜
・【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 中級編 –
など
データクリーニングの手順
一般的に、得られた生データはそのまま利用すると、不備が生じることがありそれが統計検定の結果を大きく変化させてしまうことがあります。
チェック項目として
- 文字列データがあれば数字データに変換
- 「,」とる
- 欠損データの把握
- 重複データの把握(意図的?たまたま?間違い?)
- 外れ値の検出
- 各説明変数と、目的変数の分布の確認(対数変換の必要性?)
- 外れ値除去後のデータ数の確認とインデックス番号の振り直し
といったところでしょうか・・・。
|
1 2 3 4 5 |
%matplotlib inline import numpy as np import pandas as pd import seaborn as sns |
文字列データがあれば数字データに変換と「,」とり
プログラミングでは数字データと文字列データは別物。
統計解析を行っていくうえで、これらが混ざり合っている場合には注意が必要です。(文字列データ自体は、ある変数がすべてカテゴリーデータである場合などはダミー化したりして統計に使用するため、あくまで、「混ざっているのがよくない」)
各変数にどんなデータ種別のものがあるかを調べます。
|
1 2 3 4 5 6 7 |
df.dtypes #返されるものは、下記のようなデータです。 x11 float64 x12 float64 x13 float64 y float64 dtype: object |
例えば、A列は本来小数列なのに、文字列扱いされていた場合には、
|
1 2 3 |
#文字列があった場合に、小数列に変更する #例えば、A列のみを変更する場合 df['A']=df['A'].astype(float) |
欠損値の取り扱い
欠損データの把握は、一つは、各変数の数値の個数を数えることです。
全体のデータを眺めて判断します。
|
1 |
df.describe(include='all') |
この処理で、表が出現しますので、一番上にあるcountがデータの個数になります。
この数が、変数間で違う場合に欠損値が疑われます。
また、他にも欠損値があるかないか?だけを表示する方法として、
|
1 |
df.isnull().sum() |
で、各変数に欠損値がいくつあるかを示してくれます。
欠損値の取り扱いですが、もし全体のデータの5%未満であれば、そのまま削除しても良いというのが通例のようです。
取り除くには、
|
1 2 3 4 5 6 7 8 |
すべての値が欠損値である行と列のみを削除 df = df.dropna(how='all').dropna(how='all', axis=1) 引数how='any'を指定すると、欠損値が一つでも含まれる行が削除される。デフォルトがhow='any'なので、何も指定しないとこの動作になる。 df=df.dropna(how='any') axis=1とすると列に適用。欠損値が一つでも含まれる列が削除される。 df=df.dropna(how='any', axis=1) |
他にも平均値を入れる方法
|
1 2 |
#欠損データが複数ある場合、平均値で埋めることがある df=df.fillna(df.mean()) |
気温のように連続的に変化する値の場合には平均値を使うと急激に値が変化するため欠損値を1つ前の値で埋めることもあります
|
1 |
df=df.fillna(method='ffill') |
などがあります。
重複データの取り扱い
データを記述している際に誤ってコピーアンドペーストして、いくつかのデータが重複することがあります。
もちろん、たまたま全く同じってこともありますので、闇雲に重複データを削除するのは間違いですから、ここのケースに応じた対応が必要です。
まずは重複データの把握。
|
1 |
df.duplicated().value_counts() |
重複データがある場合Trueで返されます。
ない場合はFalseで返されます。
さらに、重複データを削除する場合には、
|
1 |
df=dfF.drop_duplicates() |
を利用します。
外れ値の除去
外れ値の除去としては、ここでは2つ紹介します。
1つ目は、3σ法です。
標準偏差をσと表現しますが、3σは標準偏差✖️3のことで、この範囲内にデータ全体の99%が(正確にはもうすこし細かい数字ですが・・)含まれているとされています。
その外にあるデータを外れ値として除外するというものです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#df.columnsですべての列データのヘッダーを全て取得する #これををcolsに格納する cols=df.columns cols #for文でそれぞれをループさせる for col in cols: #平均値±標準偏差*3の値をだして、除外しないデータの上限と下減を設定 low=mean[col]-3*sigma[col] high=mean[col]+3*sigma[col] #上限値と下限値以外のデータを取得すれば、データの99%を取得可能 #_dfを外れ値除去後のデータフレーム(データ群)とする _df = df[(df[col]>low)& (df[col]<high)] |
ちなみに、元データと外れ値除去後のデータの数を比較するには、
|
1 2 |
len(df) len(_df) |
で、比較して、どれくらいデータが除去されたかをみることができます。
しかし、この3σ法の注意点は、データが原則、正規分布であることを前提としている点です。
例えば、以下のグラフのような場合
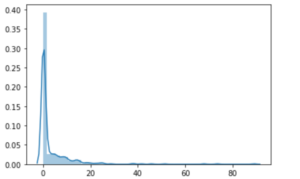
左に大きな山のある、偏ったグラフです。
平均値は、高い値に引っ張られて、中央値と大きく解離します。
この分布に対して3σ法を適応すると、低い値を過剰に外れ値として除去してしまう可能性があります。
ですので、このような分布の場合にも一律に3σ法を適応することはお勧めできません。
そこで、もうひとつ、それぞれの分布を確認しながら、外れ値を除去していくという、やや肉体系のやり方を紹介します。
先ほどのグラフをもう一度例にします。
左に大きな山があり、高い値にかなり引っ張られて、正規性がなさそうであることがわかります。
なので、高い値の1%部分だけを外れ値として除外するという方法をとります。
|
1 2 3 |
#先ほどの分布を示した行のデータをx1とします q=df1['x1'].quantile(0.99) df2=df1[df1['x1']<q] |
この処理後のデータ分布は下記のようになります。
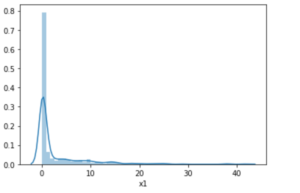
すこし、正規分布にちかくなったか?という感じです。
*わかりにくですが、先ほどまでのグラフト比較して、横軸の値が変わっていますので注意して見てください。
また、yがあまりにも正規分布から、かけ離れている(2局化分布とか)場合には、説明変数で目的変数を説明することも難しいです。
少し難しい話になりますが(飛ばしても良いです)、yが指数分布の場合には、対数変換することで正規分布にすることも可能です。
ただし、この場合は結果をみるときに対数から整数にもどして解釈する必要があります。
また、データを標準化したときに、説明変数の係数からデータの重みを考えるときに、指数変換されていると純粋な重みの比較はできなくなりますので注意が必要です。
外れ値のとりあつかい
外れ値の取り扱いで非常に重要になるのは、何を外れ値とするか?だと思います。
それは、数字や分布だけの問題ではなく、データのもつ’意味’を理解する必要があります。
この部分は、プログラミングにまかせて自動化したままにしていると、思わぬ落とし穴に落ちます。
例えば、数字的に外れ値でも、含んでおかないといけないデータもありますし、そもそもなぜその外れ値がでているのか?を考えて、含んだ方がいいかどうかを検討する必要があります。
また、ありえない数字になっていることもあります。
例えば、日本における1家庭の子供の人数というデータを見たときに、100人とかになっている場合には、データ収集時点のエラーを疑い、外れ値として削除してOKます。(多分ありえないですよね・・・www)
また、コンピュータの出始めの頃に、欠損値を99.9と表記する文化があったそうで、その文化を根強く周到されている人がデータ取得作業をおこなっていると、それがデータを歪めている可能性がありますので、こちらも注意が必要です。
もう一度いいますが、外れ値を考える場合には、データの持つ意味を理解する必要があります。
本当に外れ値として除去すべきかどうかは意味を理解して行う必要があるため、それぞれの変数を数字としてみるだけにするのではなく、意味を理解して取り扱いましょう。
インデックス番号の振り直し
外れ値除去後は、インデックス番号を振り直した方が後々、楽にデータ処理ができます。
|
1 2 |
# インデックス番号を振り直す df=df.reset_index(drop=True) |
これだけですww
新着記事
 【ポータブル電源】家族持ちなら即購入?ただし購入体験は最悪。
【ポータブル電源】家族持ちなら即購入?ただし購入体験は最悪。
 【買い!】echo show15の半年使用後レビュー
【買い!】echo show15の半年使用後レビュー
 【保存版】顎骨壊死を懸念してビスホスホネート製剤の予防的休薬は不要!?
【保存版】顎骨壊死を懸念してビスホスホネート製剤の予防的休薬は不要!?
コメントをどうぞ

